

Biochimie
5. STRUCTURE ET FONCTION DES MACROMOLECULES
|
MACROMOLECULES Molécules organiques complexes se formant dans la cellule à partir de molécules organiques simples |
Quatre grandes classes de macromolécules organiques complexes :
Glucides
Lipides
Protéines
Acides nucléiques
Ces molécules sont souvent énormes au niveau moléculaire, comme les protéines qui peuvent compter des milliers d’atomes unis par des liaisons covalentes et représenter de véritables colosses moléculaires dont la masse peut dépasser 100.000 µ. Les biologistes utilisent le terme macromolécules pour les désigner.
Malgré leur taille et leur complexité, les biochimistes sont parvenus à déterminer la structure détaillée d’un grand nombre d’entre-elles.
Parvenir à établir la structure de ces molécules permet de saisir plus facilement leur fonction.
Dans ce chapitre, nous abordons leur structure et leur fonction qui comme toujours en Biologie sont indispensables.
5.1 Les macromolécules sont des polymères synthétisés à partir de monomères.
Les quatre grandes classes de macromolécules sont des polymères, ceux-ci sont des molécules constituées d’un grand nombre d’unités structurales identiques ou semblables appelées monomères, rattachés par des liaisons covalentes. Dans certains cas, des monomères isolés remplissent une fonction qui leur est propre.
5.1.2 Synthèse et dégradation des polymères.
Les classes de polymères macromoléculaires diffèrent par la nature de leurs monomères, mais ceux-ci sont liés entre eux par la réalisation d’un type particulier de réaction de condensation que l’on appelle déshydratation, car au cours de celle-ci il y a perte d’une molécule d’eau. En fait, chaque fois que deux polymères s’unissent l’un d’entre eux libère un groupe hydroxyle (-OH) et l’autre un atome d’hydrogène (-H).
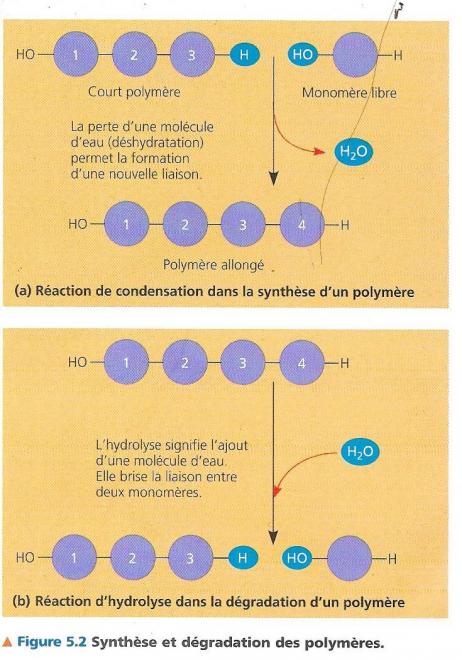
Lors de la construction d’un polymère, chaque fois un monomère est additionné à la chaîne, par cette réaction, qui est ainsi répétitive. Pour réaliser celle-ci, de l’énergie est nécessaire ainsi que des enzymes qui sont des protéines agissant comme des catalyseurs en augmentant la vitesse réactionnelle. La réaction inverse de scission des polymères s’appelle hydrolyse. L’addition de molécule d’eau rompt la condensation qui s’est établie par liaison covalente des monomères : un atome d’hydrogène provenant de l’eau s’attache à un monomère tandis qu’un groupement hydroxyle s’attache au monomère adjacent. Lors de la digestion, les molécules constitutives des aliments sont beaucoup trop grosses pour entrer dans les cellules. Très souvent ce sont des réactions d’hydrolyse enzymatique qui libèrent les monomères des polymères. Ceux-ci passent alors la barrière intestinale pour accéder à la circulation sanguine qui les distribue à chaque cellule. Ces monomères passent la membrane cellulaire et peuvent à nouveau être condensés en polymères qui assureront diverses fonctions de la cellule.
5.1.3 La diversité des polymères
Des milliers de macromolécules différentes sont présentes dans les cellules et varient d’un tissu à l’autre. Des frères et des sœurs différents par leurs macromolécules, notamment l’ADN et les protéines, les différences entre macromolécules étant plus importantes entre personnes sans lien de parenté et d’autant plus entre espèces…
La diversité des macromolécules dans le monde vivant est considérable et tend vers l’infini. A l’image des mots composés des lettres de l’alphabet, la diversité des macromolécules provient de la combinaison de monomères en chaînes. Toutes les protéines sont composées par combinaison de 20 acides aminés fondamentaux. Ces acides aminés sont condensés en chaînes généralement bien plus longues que le plus long des mots, ce qui rend leur potentiel de diversité encore bien plus important que celui des mots.
Les macromolécules des quatre catégories de macromolécules peuvent s’associer de différentes manières. A l’image des macromolécules comportant comme monomères des glucides simples : glycolipides, glycoprotéines, les lipoprotéines constituent des associations de lipides et de protéines et les glucides sont présents dans les acides nucléiques.
Les macromolécules complexes possèdent des propriétés que l’on ne retrouve pas dans leurs monomères, c’est l’émergence évoquée dans le chapitre d’introduction.
5.2 Les glucides servent de sources d’énergie et de matériaux de structure.
On sépare les glucides en 3 classes :
- Les monosaccharides : un seul monomère constitutif
- Les disaccharides : deux monomères constitutifs condensés : deux monosaccharides
- Les polysaccharides faits de plusieurs monomères condensés : une grande quantité de monosaccharides.
5.2.1 Les monosaccharides et les disaccharides
5.2.1.1 Monosaccharides
En général, les monosaccharides ont une formule moléculaire qui est un multiple de CH20 à l’exemple du glucose C6H12O6
Le glucose est le monosaccharide le plus courant, il joue un rôle capital dans la chimie des êtres vivants. Sa structure a les caractéristiques suivantes :
- Un groupement carbonyle (>C=O)
- De nombreux groupements hydroxyles
Un groupe carbonyle est situé soit dans la chaîne (noté R1—CO—R2) soit en bout de chaîne (noté R—CHO). On parle donc de deux familles chimiques de composés présentant le groupe carbonyle qui sont respectivement la famille des cétones et celle des aldéhydes.
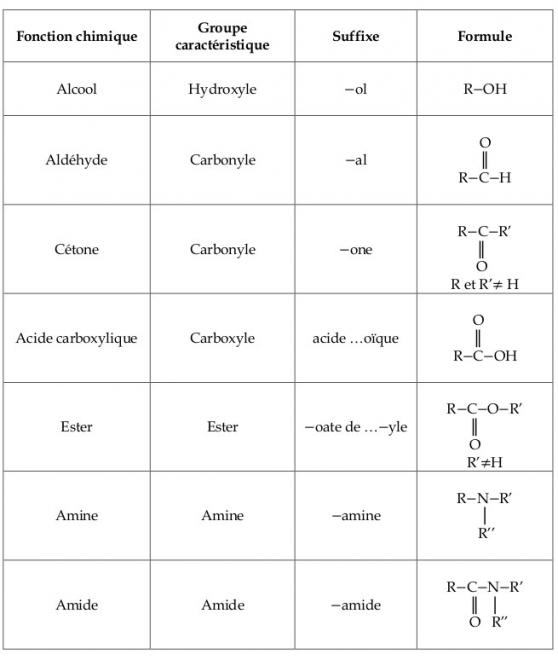
On peut encore mentionner la liaison éther
Les éther-oxydes, appelés aussi plus simplement éthers, sont des composés organiques de formule générale R-O-R', où R et R' sont des groupes alkyle.

Diverses caractéristiques sont utilisées pour classer les monosaccharides.
- Selon la position du groupement carbonyle, un monosaccharide est soit :
- Un aldose (le carbonyle est un aldéhyde)
- Un cétose (le carbonyle est une cétone)
Le glucose est un aldose, alors que le fructose (le plus sucré des sucres), un isomère de structure du glucose, est un cétose.
- La plupart des noms de monosaccharides se terminent par « ose ».
- La longueur des chaînes carbonées est un autre facteur de classification des monosaccharides.
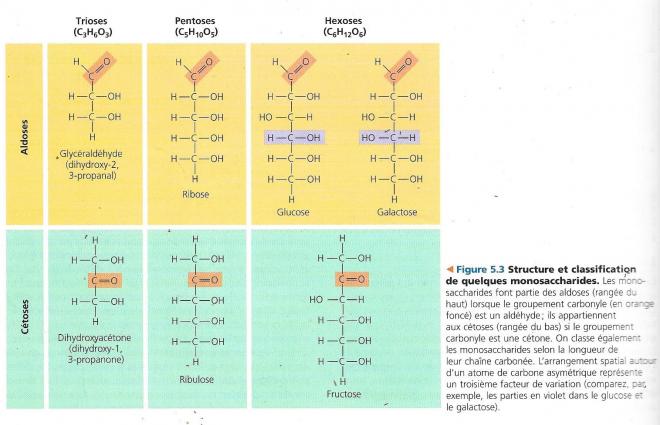
Ceux-ci sont constitués de 3 à 7 atomes de carbone ; glucose et fructose à 6 atomes de carbone sont nommés hexoses ; De la manière la plus courante, on a :
- Les hexoses à 6 atomes de C
- Les pentoses à 5 atomes de c
- Les trioses à 3 atomes de C
Ces molécules possèdent des isomères optiques en sorte qu’il existe 16 hexoses différents.
- Structure chimique des hexoses
Deux structures sont à retenir, elles sont caractérisées par :
- Une chaîne verticale de 6 carbones numérotée de 1 à 6 de haut en bas
- Complétée avec des H et des OH et soit une fonction cétone sur le carbone 2 = cétoses ou une fonction aldéhyde sur le carbone 1 = aldoses
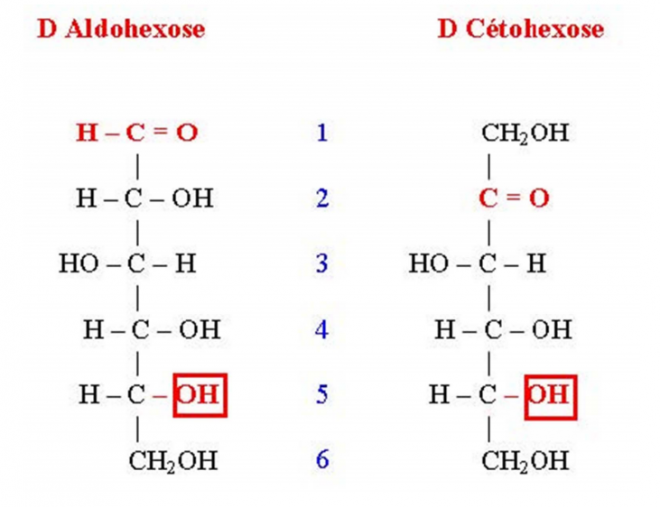
Nous avons sur la figure : le glucose, un aldohexose et le fructose un cétohexose.
- L’arrangement spatial autour d’un atome, parfois asymétrique, contribue à la diversité des monosaccharides
Un atome de carbone asymétrique est un atome de Carbone lié à quatre partenaires différents. : des groupes ou de simples atomes.
Le glucose et le galactose, par exemple, ne diffèrent que par la disposition de leurs groupements hydroxyle autour d’un carbone asymétrique. Cette différence peut sembler minime, mais elle suffit à donner à ces deux monosaccharides une forme et un comportement distincts
Le même principe à retenir pour les trioses et les pentoses, il suffit d’adapter le nombre de carbones
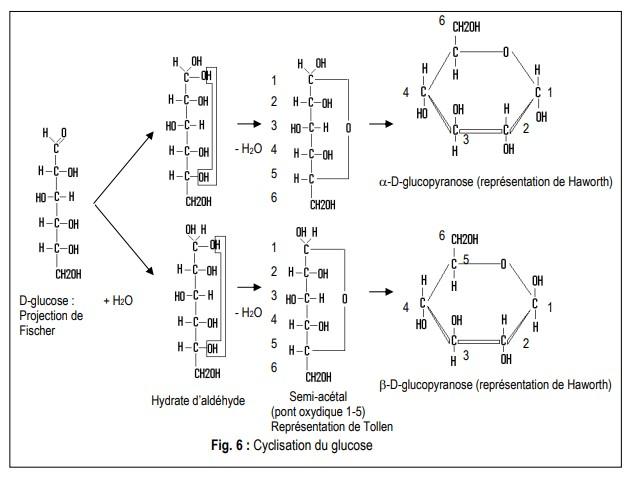
Cette représentation linéaire des hexoses (et des monosaccharides en général) se présentent, en réalité, majoritairement sous une forme cyclique en solution.
Cyclisation du glucose, pareil pour tous les aldoses à 6 carbones, le mécanisme permet de ne pas retenir par cœur les molécules cycliques
Cyclisation des aldohexoses
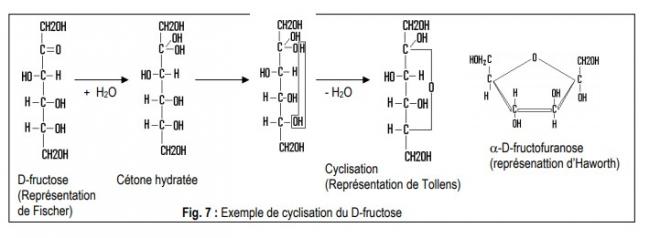
Cyclisation des cétohexoses avec hydratation préalable
Monosaccharides et en particulier le glucose sont des nutriments aux cellules. Ils fournissent de l’énergie au cours du processus de respiration et de fermentation cellulaire. Leur squelette carboné peut également servir de base à la synthèse d’autres petites molécules comme les acides aminés et les acides gras. Si leurs atomes de carbone ou leur énergie ne sont pas directement utilisés pour le travail cellulaire, ils s’incorporent à titre de monosaccharides à des disaccharides ou des polysaccharides.
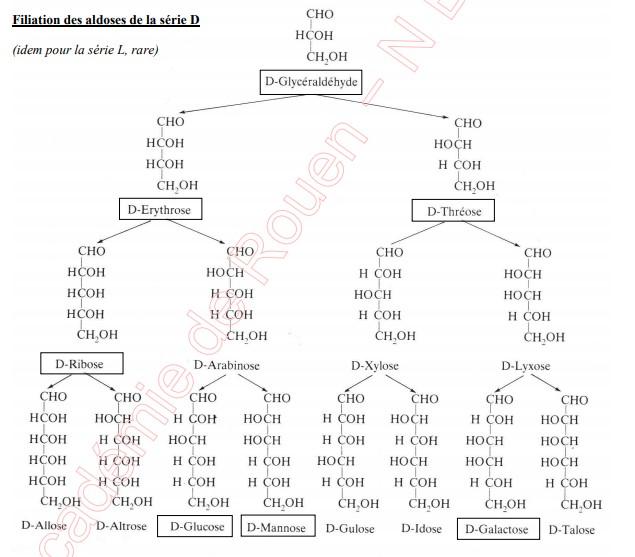
Pour mémoire, on observera les deux filiations D (aldoses et cétoses)
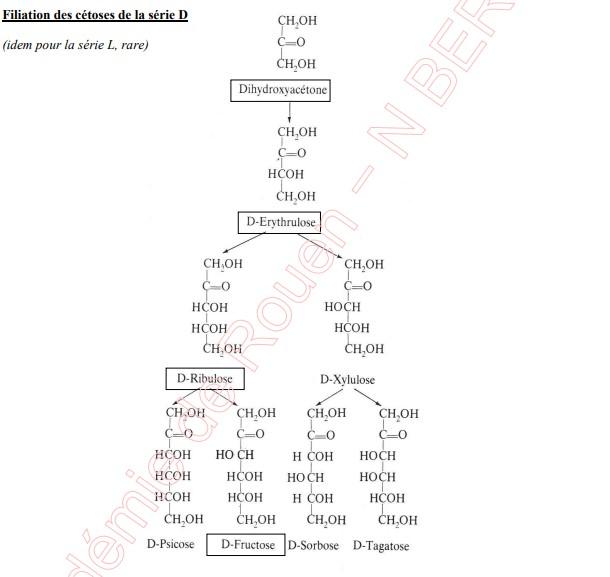
5.2.1.2 Disaccharides
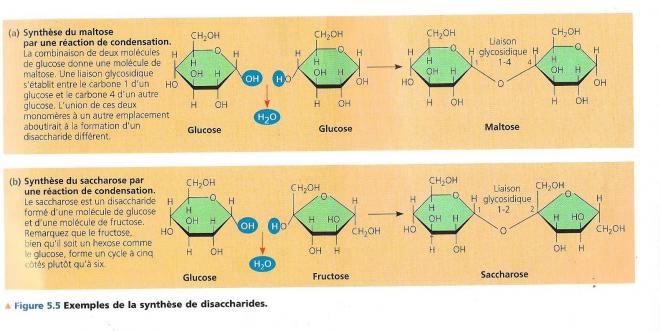
Un disaccharide se compose de deux monosaccharides liés par une réaction de condensation telle que nous l’avons évoquée dans le paragraphe précédent. Quelques exemples
- Maltose = condensation de deux molécules de glucose
- Saccharose = condensation d’une molécule de glucose et de fructose, il voyage des feuilles des plantes aux organes non photosynthétiques
- Lactose = condensation d’une molécule de glucose et d’une molécule de galactose : sucre du lait
La liaison de condensation entre les deux molécules de glucose du maltose se réalise entre le carbone 1 de la première molécule de monosaccharide et le carbone 4 de la seconde.
On parlera dans ce cas de liaison glycosidique 1- 4
5.2.2 Polysaccharides
Les polysaccharides sont des polymères, de quelques centaines à quelques milliers de monosaccharides unis par des liaisons glycosidiques.
Ce sont soit :
- Des substances de réserve hydrolysés en fonction des besoins de la cellule
- Des matières premières destinées à l’édification de structures protégeant la cellule ou l’organisme entier
L’architecture et la fonction des polysaccharides sont déterminés par la nature des monomères et la disposition des liaisons glycosidiques.
5.2.2.1 polysaccharides de réserve
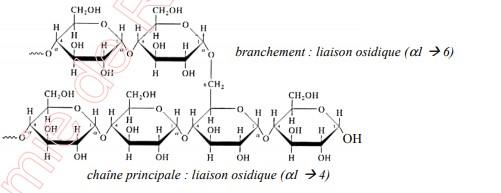
- L’amidon est le polysaccharide de réserve glucidique des végétaux, c’est une molécule entièrement formée de glucose. - Polysaccharide de réserve glucidique des végétaux
- Macromolécule entièrement formée de glucose
- Les monomères qui le composent sont unis par des liaisons glycosidiques 1—4 entre carbone 1 d’une molécule de glucose et a de la molécule suivante.
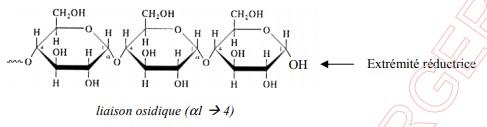
L’angle de ces liaisons donne une forme hélicoïdale au polymère
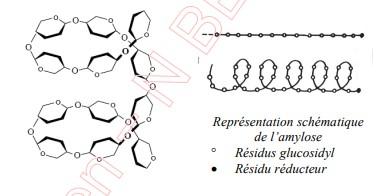
L’amidon a en fait deux composantes, la première correspondant à la structure non ramifiée ci-dessus et s’appelle amylose.
L’autre composante s’appelle amylopectine et est faite du même type de structure linaire hélicoïdale ramifiée comportant des liaisons glycosidiques 1—6 aux embranchements.
 Les végétaux accumulent l’amidon sous forme de granules dans des structures cellulaires appelées plastes comme les chloroplastes. En synthétisant l’amidon, les végétaux peuvent accumuler des réserves de glucose, source d’énergie cellulaire importante. La cellule puise dans ces réserves au moyen de l’hydrolyse des liaisons entre monomères de glucose. La plupart des animaux, y compris les humains possèdent des enzymes qui hydrolysent l’amidon des nutriments et libèrent le glucose, qui servira de nutriment aux cellules. Les pommes de terre et les céréales (maïs, riz, blé, sorgho, millet …) sont les principales sources d’amidon dans le régime alimentaire des humains.
Les végétaux accumulent l’amidon sous forme de granules dans des structures cellulaires appelées plastes comme les chloroplastes. En synthétisant l’amidon, les végétaux peuvent accumuler des réserves de glucose, source d’énergie cellulaire importante. La cellule puise dans ces réserves au moyen de l’hydrolyse des liaisons entre monomères de glucose. La plupart des animaux, y compris les humains possèdent des enzymes qui hydrolysent l’amidon des nutriments et libèrent le glucose, qui servira de nutriment aux cellules. Les pommes de terre et les céréales (maïs, riz, blé, sorgho, millet …) sont les principales sources d’amidon dans le régime alimentaire des humains.
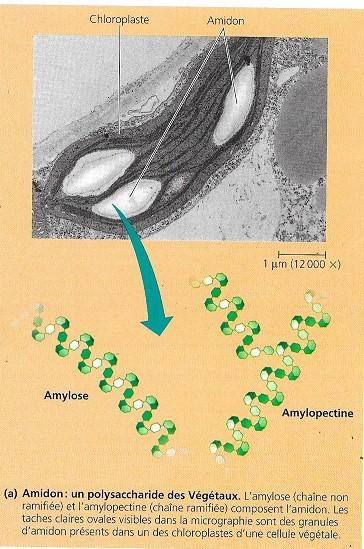
La proportion des amidons tourne autour de 70% amylopectine/30% amylose.
- Le glycogène est un polysaccharide particulièrement utilisé par les animaux pour stocker le glucose, Il ressemble à l’amylopectine mais est plus ramifié.
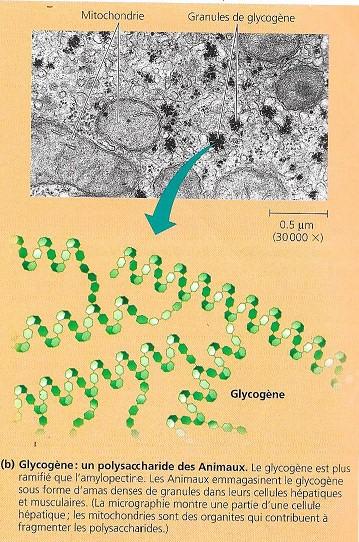
Les ramifications des macromolécules de glycogène se rencontrent tous les 10 à 12 monomères chez le glycogène, tous les 30 monomères pour l’amylopectine. Les humains et les autres vertébrés emmagasinent du glycogène surtout dans les cellules de leur foie et celles de leur muscle. L’hydrolyse de ce polysaccharide libère du glucose dans ces cellules lorsque le besoin en monosaccharide augmente. Cette énergie de réserve ne soutient cependant pas longtemps un animal. La réserve de glycogène d’un humain s’épuise en un jour environ si aucun aliment ne vient la reconstituer.
5.2.2.2 Polysaccharides structuraux
- Certains organismes fabriquent des matériaux solides à partir de polysaccharide. Un exemple en est la cellulose chez les végétaux, c’est un constituant important de leur paroi robuste des cellules végétales. C’est le composé organique le plus important sur terre, les végétaux en produisent 100milliards de tonnes de cellulose par année. La cellulose est un polymère du glucose comme l’amidon, mais leurs liaisons glycosidiques sont différentes.
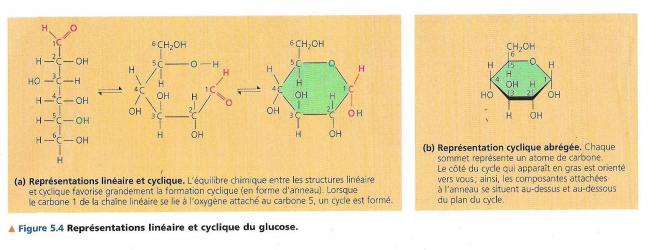
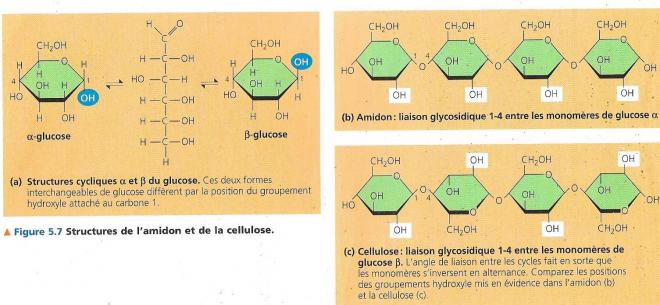 Le cycle du glucose existe, en fait, sous deux formes car le groupement hydroxyle lié au carbone 1 peut se situer soit en dessous ou au-dessus du plan de l’anneau : ces deux formes cycliques du glucose se nomment respectivement α et β. Dans l’amidon, tous les monomères ont la configuration α, dans la cellulose, tous les monomères ont la configuration β, chaque monomère de glucose étant ainsi inversé par rapport aux monomères adjacents.
Le cycle du glucose existe, en fait, sous deux formes car le groupement hydroxyle lié au carbone 1 peut se situer soit en dessous ou au-dessus du plan de l’anneau : ces deux formes cycliques du glucose se nomment respectivement α et β. Dans l’amidon, tous les monomères ont la configuration α, dans la cellulose, tous les monomères ont la configuration β, chaque monomère de glucose étant ainsi inversé par rapport aux monomères adjacents.
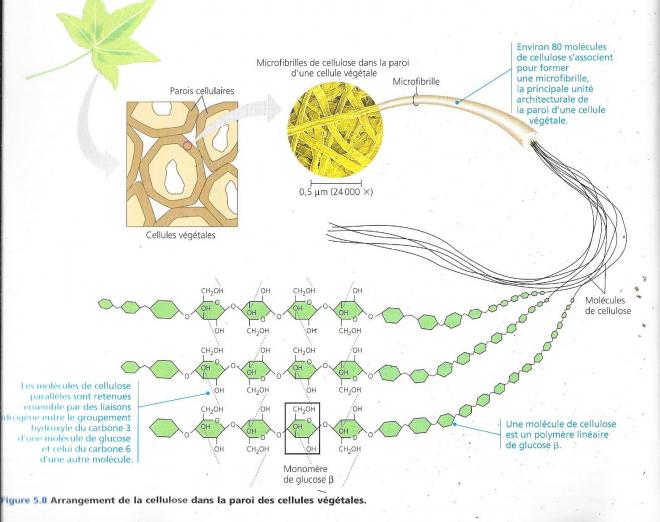
Ayant des liaisons glycosidiques différentes, les molécules d’amidon et de cellulose ont des formes tridimensionnelles distinctes. La molécule d’amidon est principalement hélicoïdale tandis que la molécule de cellulose est droite et n’est jamais ramifiée. D’autre part, les divers groupements hydroxyles des monomères peuvent interagir en formant des liaisons hydrogène.
Dans la paroi des cellules végétales, de telles molécules parallèles s’associent par pont hydrogène pour former des microfibrilles. Ces microfibrilles vont ensuite s’orienter pour former des couches perpendiculaires les unes par rapport aux autres et constituent un matériau de soutien résistant et fort important pour les végétaux. Les humains utilisent le bois riche en cellulose comme matériaux de construction ou comme source d’énergie calorifique.
Les enzymes hydrolytiques de l’amidon sont incapables d’hydrolyser les liaisons β des molécules de cellulose, car elles ont des conformations différentes. Très peu d’organismes produisent des enzymes capables d’hydrolyse des molécules de cellulose…C’est un atout important considérant le rôle structural de cette substance.
Les êtres humains ne peuvent pas dégrader la cellulose, celle-ci passe directement des aliments à la matière fécale. Cependant elle a une fonction bénéfique sur le fonctionnement de l’intestin. Dans les aliments commerciaux, sa présence est signalée sous le terme « fibres »
Par contre, certains vertébrés comme la vache possèdent dans les premiers compartiments de leur tube digestif (panse et bonnet) des bactéries capables d’assumer cette hydrolyse et peuvent libérer le glucose qui servira ainsi de nutriment à la vache. Les termites possèdent dans leur intestin des micro-organismes qui en sont également capables, ce qui leur permet de digérer le bois, certaines peuvent également hydrolyser la cellulose et assurent ainsi une fonction essentielle à la circulation de la matière dans les écosystèmes.
- La chitine est un autre polysaccharide de structure important, les Arthropodes comme les insectes, les Arachnides, les Crustacés synthétisent la chitine pour construire leur exosquelette. Un exosquelette est une structure rigide qui recouvre les parties molles d’un animal. La chitine pure ressemble à du cuir, mais elle durcit lorsqu’elle est imprégnée de carbonate de calcium ; On trouve également de la chitine chez les champignons (Eumycètes). Ceux-ci utilisent la chitine en lieu et place de la cellulose pour construire leur paroi cellulaire. La chitine ressemble à la cellulose, exception faite que son monomère de glucose possède une chaîne latérale contenant de l’azote.

5.3 Les lipides forment un groupe de molécule d’aspects variés
La classe des lipides est formée de molécules plus ou moins complexes qui ne sont pas des polymères. C’est un groupe de molécules qui sont regroupées selon une caractéristique commune importante : ils n’ont pas ou très peu d’affinité pour l’eau, par leurs caractéristiques moléculaires. Malgré qu’ils comportent quelques liaisons polaires associées à l’oxygène, ils sont en majorité constitués d’hydrocarbures. Ils sont beaucoup plus petits que les vrais macromolécules (polymères). Ils forment un groupe très hétérogène par leurs structures et fonctions, mais nous allons ici étudier trois familles très importantes
- Les graisses
- Les phospholipides
- Les stéroïdes
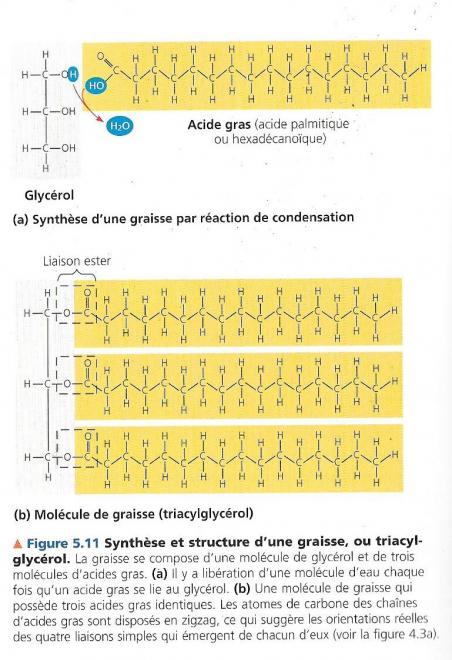
5.3.1 Les graisses (glycérides ou acylglycérols)
- Sont de grosses molécules
- Ne sont pas des polymères
- leurs petites molécules constitutives ne sont pas ds monomères
- Ces petites molécules sont liées par des réactions de condensation
Ces petites molécules sont :
- Le glycérol
- Les acides gras.
Le glycérol est
- Un alcool à trois atomes de carbone
- Chaque atome de carbone possède un groupement hydroxyle
Les acides gras sont
- Des longues chaînes d’hydrocarbure de 16 à 18 atomes de carbone
- Des acides portant à l’extrémité de leur chaîne un groupement carboxylique
Les liaisons C-H non polaires de la chaîne hydrocarbonée expliquent le caractère hydrophobe de la molécule
Les graisses ne se dissolvent pas dans l’eau car l’eau établi des liaisons hydrogène entre elles repoussant les graisses.
Les acides gras varient entre eux par
- Le nombre d’atomes de carbone
- Le nombre et la position des doubles liaisons
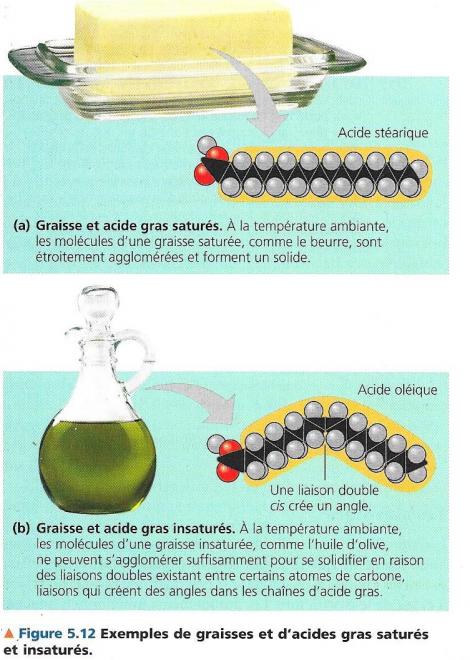
Saturation et insaturation des acides gras
- Saturés :
- Pas de liaisons doubles
- Un maximum d’atomes d’hydrogène
= saturation en atomes d’hydrogène
- Insaturés
- Présence de liaisons doubles
- Les liaisons doubles diminuent le nombre d’atomes d’hydrogène
Monoinsaturés : une liaison double un atome d’H en moins
Polyinsaturés : plusieurs liaisons double plusieurs atomes d’hydrogène en moins
L’insaturation introduit des formes angulaires dans la chaîne hydrocarbonée.
La figure précédente montre pourquoi le beurre est solide à température ambiante (graisse saturée, acide gras linéaire) et non l’huile d’olive (acides gras insaturés, donc coudes dans la molécule).
Le rôle essentiel des graisses est de stocker de l’énergie, leurs molécules constitutives ressemblent aux hydrocarbures de l’essence…
Les graisses sont des formes plus compactes de stockage d’énergie, par rapport à l’amidon, elles stockent plus de deux fois d’énergie par gramme.
Les végétaux ne se déplacent pas, le volume des zones de stockage d’énergie n’a pas beaucoup d’avantage. Par contre pour les animaux qui doivent transporter leurs réserves, les graisses sont intéressantes ; ces graisses sont alors stockées dans des cellules adipeuses qui gonflent ou rétrécissent en fonction du volume à stocker. Les graisses servent aussi d’amortisseur pour protéger des organes vitaux comme le rein. Le tissu adipeux sous-cutané sert également d’isolant thermique (phoques ou ce trait est particulièrement important)
5.3.2 Les phosphoglycérolipides.
Ils ressemblent aux graisses, mais ne comportent que deux chaines d’acide gras. En effet, le troisième carbone hydroxylé du glycérol est lié (par son hydroxyle) à un groupement phosphate porteur de charges négatives.
De petites molécules polaires ou chargées peuvent se fixer au phosphate pour ainsi former un phosphoglycérolipide.
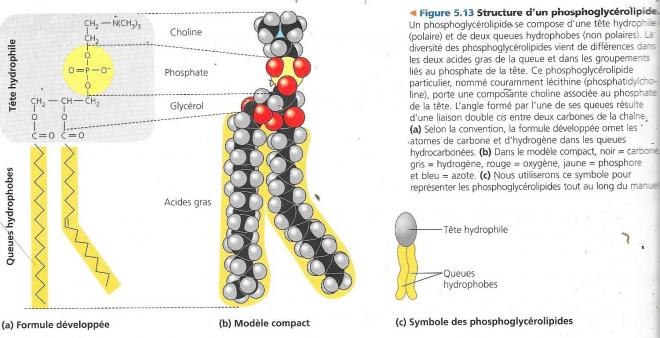 Les phosphoglycérolipides ont un comportement ambivalent vis-à-vis de l’eau, la partie chargée ou polaire forme une tête hydrophile (affinité pour l’eau) leur queue hydrocarbonée étant hydrophobe ; dans l’eau ces molécules forment des agrégats en double couche qui cachent leurs parties hydrophobes.
Les phosphoglycérolipides ont un comportement ambivalent vis-à-vis de l’eau, la partie chargée ou polaire forme une tête hydrophile (affinité pour l’eau) leur queue hydrocarbonée étant hydrophobe ; dans l’eau ces molécules forment des agrégats en double couche qui cachent leurs parties hydrophobes.
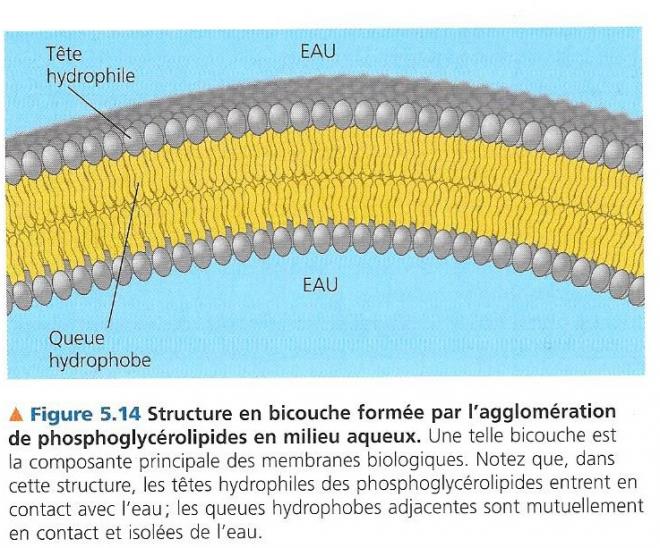
A la surface des cellules, les phosphoglycérolipides s’organisent en bicouches. Les parties hydrophobes se font face et les parties hydrophiles se disposent dans la solution aqueuse de part et d’autre de la surface de la cellule. Ce dispositif constitue la matrice de la membrane cellulaire.
A nouveau, la structure implique la fonction.
5.3.3 Les stéroïdes
Lipides caractérisés par un squelette carboné constitué de 4 cycles accolés. C’est leur peu d’affinité pour l’eau qui justifie leur classement parmi les lipides, et non leur structure chimique ;
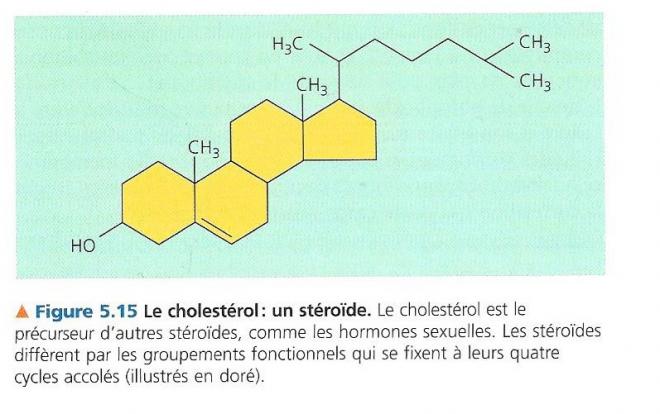
Les groupements fonctionnels attachés à l’ensemble des cycles varient d’un stéroïde à l’autre. Le cholestérol est un stéroïde présent dans la membrane cellulaire et dans la bile. Il constitue également le précurseur d’autre stéroïdes comme de nombreuses hormones dont les hormones sexuelles des vertébrés. Ce cholestérol est une molécule essentielle pour les animaux. Un taux sanguin élevé de cette molécule peut causer de l’athérosclérose.
Chimiquement, les acides gras trans sont composés des mêmes atomes que leurs diastéréoisomères : les acides gras cis. Cependant, les AG insaturés trans sont beaucoup moins présent à l'état naturel par rapport aux AG insaturés cis.
Et ils ont une géométrie spatiale différente : dans les molécules d'acides gras trans, les doubles liaisons entre atomes de carbone (caractéristiques de tous les acides gras insaturés) sont en configuration trans au lieu d'être en configuration cis, ce qui leur donne une forme plutôt droite au lieu d'être courbée.
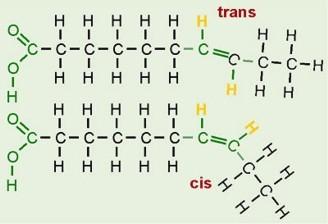
Cette particularité les rend moins fluides et leur donne une température de fusion plus élevée que la forme cis : ils sont donc plus solides à température ambiante, ce qui est une propriété recherchée par l'industrie agroalimentaire, notamment pour la préparation de margarines. Ils diminuent également la fluidité membranaire s'ils sont intégrés dans la bicouche lipidique. Les gras saturés et les gras trans ont un effet négatif sur la santé en influençant le taux de cholestérol.
Les acides gras naturels sont en configuration cis
5.4 Les protéines possèdent de nombreux niveaux de structure, ce qui leur confère des fonctions très diversifiées
Les protéines sont très importantes dans les organismes, elles représentent au moins 50% du poids sec des cellules.
Elles assument diverses fonctions
- Accélérer les réactions chimiques cellulaires
- Soutiennent les tissus
- Emmagasinent et transportent les substances
- Transmettent des communications cellulaires
- Permettent de produire le mouvement
- Défendent l’organisme contre les substances et organismes extérieurs

Un de leurs rôles les plus important est celui de catalyseur des réactions chimiques cellulaires sous la forme d’enzymes. Ces enzymes ont des réactions répétées, elles sont le moteur du fonctionnement de l’organisme.
L’organisme humain, par exemple, possède des milliers de protéines différentes, de structures différentes et de fonctions différentes. Ce sont les molécules les plus complexes que l’on connaisse, comme leurs structures sont diverses, leur structure tridimensionnelle également.
5.4.1 Les polypeptides.
Diversifiées, les protéines sont cependant des polymères de la même série d’acides aminés (20 acides aminés différents suffisent à former la presque totalité des protéines). Les polymères d’acides aminés se nomment polypeptides. Une protéine est constituée d’un ou plusieurs polypeptides qui adoptent une conformation particulière.
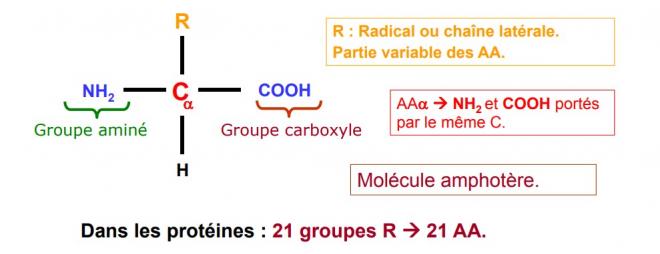
Un acide aminé est une molécule organique qui possède des groupements carboxyle et amine. Au centre de l’acide aminé se trouve un atome de carbone asymétrique appelé carbone α.
Sur cet atome se fixent 4 atomes ou groupes différents
- Un groupement amine
- Un groupement carboxyle
- Un atome d’hydrogène
- Un groupement radical R variable.
Le groupement R est également appelé chaîne latérale et est différent pour chaque acide aminé. La figure suivante présente les 20 acides aminés qu’utilise la cellule pour fabriquer des milliers de molécules.
Les groupements amine et carboxyle y sont présentés sous forme ionisée, qui est celle qui prévaut dans les conditions de pH cellulaire.
Le radical R peut aussi être un simple atome d’hydrogène comme dans la glycine qui est le seul acide aminé ne comportant pas de carbone asymétrique étant donné que le carbone porte ainsi deux atomes d’hydrogène α.
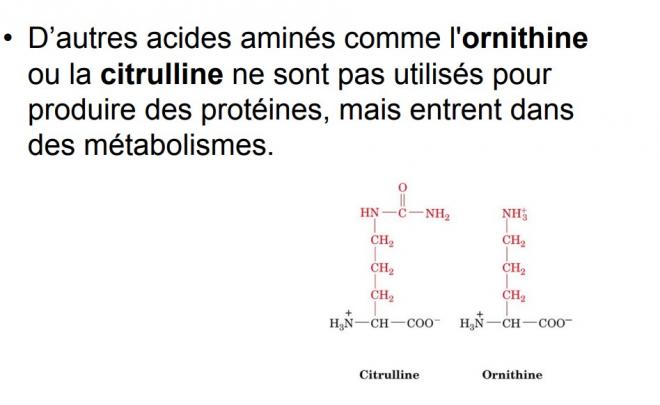
Les organismes possèdent d’autres acides aminés qui sont parfois incorporés dans les protéines et d’autres ne s’y incorporant pas. Comme ils sont relativement rares, nous ne les avons pas mentionnés.
Les propriétés physiques et chimiques de la chaîne latérale déterminent les caractéristiques particulières d’un acide aminé.
La figure qui suit classe les acides aminés d’après les propriétés de leur chaîne latérale.
Premier groupe : R non-polaire donc hydrophobe
Second groupe : R polaire donc hydrophile
Troisième groupe : R acide ou basique.

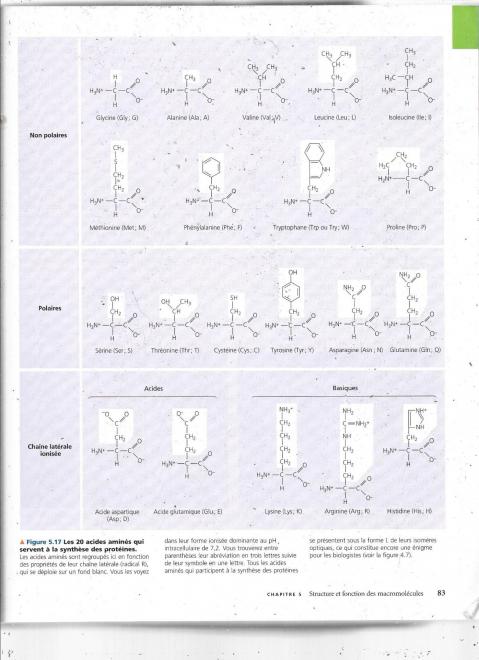
Parmi les acides aminés du troisième groupe, ceux qui ont une dénomination qui commence par acide « « portent une chaîne latérale portant une chaîne latérale ayant un groupement carboxyle qui a tendance ( moins que le carboxyle du carbone α )à s’ioniser au pH ( environ 7) cellulaire. La chaîne de ces acides aminés est donc généralement négative. Les acides aminés basiques, eux, ont une chaîne latérale généralement chargée positivement car l’atome d’azote a accepté un proton supplémentaire. Tous les acides aminés possèdent un groupe acide COOH et un groupe basique aminé, les termes acide et basique faisant référence à la chaîne latérale. Ces acides aminés acides et basiques sont hydrophiles par la charge de cette chaîne latérale.
5.4.2 Les polymères d’acides aminés.
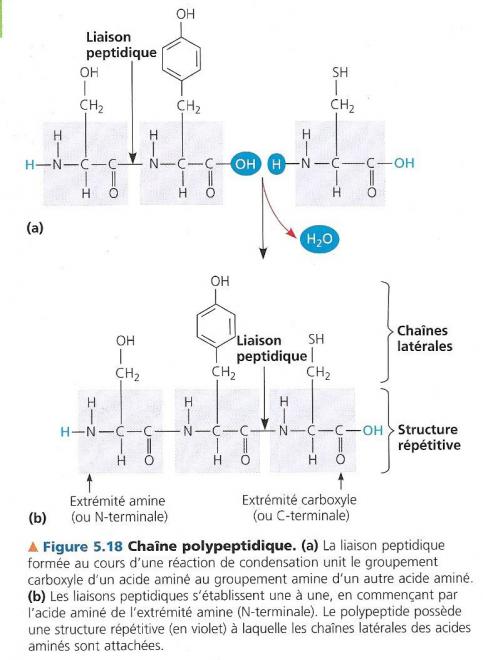
Voyons comment les acides aminés se lient pour former des polymères : Lorsque le groupement carboxyle de l’un rencontre le groupement amine de l’autre, une enzyme peut favoriser leur union en catalysant une réaction de condensation. Avec perte d’une molécule d’eau. Une liaison covalente appelée liaison peptidique ou chaîne polypeptidique s’établit ainsi grâce aux liaisons entre eux.
Lorsque cette réaction de condensation se répète encore et encore, un polymère de différents acides aminés se forme, on le nomme polypeptide.
Par convention, on « lit » le polypeptide en considérant que son extrémité aminée se trouve à gauche et son extrémité carboxylée à droite. La chaîne polypeptidique porte ainsi des différentes chaînes latérales des acides aminés individuels
La longueur d’une chaîne polypeptidique va de quelques -uns à plus d’un millier de monomères. Chaque polypeptide spécifique possède une séquence linéaire d’acides aminés. L’immense diversité des polypeptides présents dans la nature provient de la capacité des cellules à utiliser un nombre limité d’acides aminés et à les rassembler en polymères selon une variété étonnante de séquences comme nous allons le voir.
5.4.3 Détermination de la séquence ders acides aminés dans un polypeptide.
La technique initiée par Frederick singer (prix Nobel en 1958 et 1980) consiste à scinder le polypeptide en fragments de plus en plus petits, c’est de cette manière qu’il parvint à déterminer la séquence en acides aminés des deux polypeptides constitutifs de l’hormone Insuline
- Action d’enzymes et de catalyseurs qui coupent le polypeptide en des endroits spécifiques sans les hydrolyser totalement. Obtention d’une première série de fragments
- Ces fragments sont soumis à chromatographie pour les séparer.
- Nouvelle hydrolyse partielle en d’autres endroits spécifiques et obtention d’un second groupe de fragments
- Utilisation de méthodes chimiques pour déterminer la séquence en acides aminés de ces fragments.
- Recherche dans ces fragments de bouts qui peuvent se chevaucher

Singer et ses coéquipiers furent, après des années d’efforts, capables de reconstituer la structure primaire complète de la chaîne polypeptidique α ( 21 acides aminés) et de la chaîne polypeptidique β (30 acides aminés) constituant l’insuline. Cette procédure a depuis été automatisée et depuis 2003, on est capable de synthétiser des protéines artificielles.
5.5 Conformation et fonction d’une protéine
5.5.1 Introduction
A partir de la séquence en acides aminés d’un polypeptide, comment peut-on déterminer la conformation et la fonction d’une protéine. Le terme polypeptide ne signifie pas protéine. Une protéine fonctionnelle n’est pas seulement un polypeptide, mais un ou plusieurs polypeptides entortillés pliés et enroulés, de façon à créer une protéine de forme unique. C’est cependant la séquence des acides aminés qui détermine la conformation tri-dimensionnelle que la protéine adoptera.
Lorsqu’un polypeptide est synthétisé, les interactions chimiques entre les radicaux provoquent un certain nombre de repliement (diverses liaisons chimiques : VDW, Hydrogène, etc…) Ces interactions dépendent des séquences d’acides aminés. De nombreuses protéines sont « globulaires » (grossièrement sphériques), d’autres sont dites « fibreuses ». A l’intérieur de ces catégories, d’innombrables variations sont possibles. La fonction d’une protéine repose :
- Sur sa conformation
- Très souvent sur sa capacité de reconnaître une molécule et de se lier à elle (exemple des anticorps ou des enzymes qui reconnaissent et se lient à un substrat spécifique), un cas particulier est le fait que certaines molécules comme les endorphines peuvent se lier à des protéines réceptrices spécifiques de la surface des cellules nerveuses des humains. Cela provoque l’euphorie et apaise la douleur. La morphine, l’héroïsme et d’autres opiacés peuvent imiter le rôle de ces endorphines parce qu’elles ont une forme similaire.
5.5.2 Les quatre niveaux de l’organisation structurale des protéines.
Nous pouvons reconnaître dans l’architecture complexe d’une protéine 3 niveaux d’organisation structurale intégrés : un niveau primaire, un niveau secondaire et un niveau tertiaire. Un quatrième niveau, la structure quaternaire apparaît quand une protéine se compose de deux ou plusieurs chaînes polypeptidiques.
5.5.3 L’anémie à hématies falciformes, un simple changement dans la structure primaire.
Certains acides aminés peuvent être changé dans la séquence primaire d’une protéine sans affecter. Cependant, un petit changement dans la structure primaire d’une protéine peut aussi avoir des effets énormes car la protéine peut voir sa conformation modifiée et sa fonction entravée. La cause ultime de l’anémie à hématies falciformes est de cette nature au niveau de la chaîne polypeptidique β de ‘hémoglobine normale. Un seul acide aminé (l’acide glutamique assez fortement hydrophile) est remplacé par la valine (très hydrophobe). L‘hémoglobine est la protéine des globules rouges ayant pour fonction de transporter le dioxygène. Le remplacement de l’acide aminé modifie la forme du globule rouge qui cristallise alors lorsque le taux de dioxygène diminue. Cristallisés, ces globules rouges provoquent des douleurs et entravent la circulation sanguine
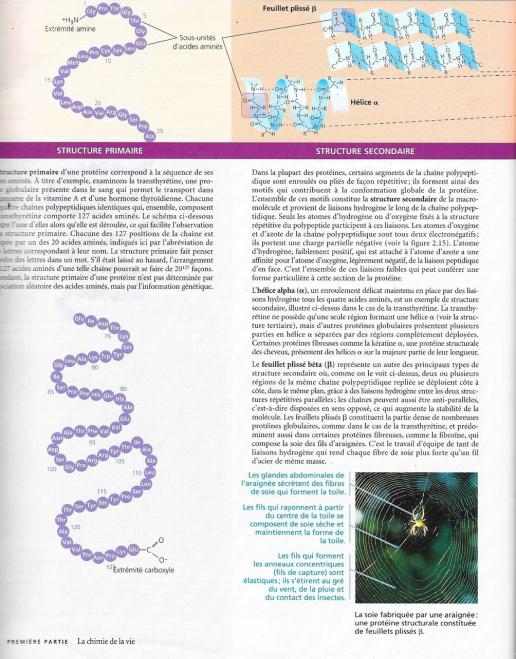
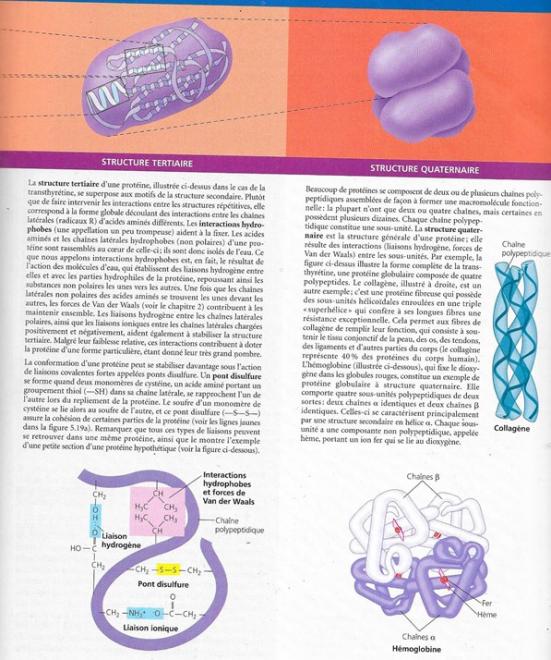
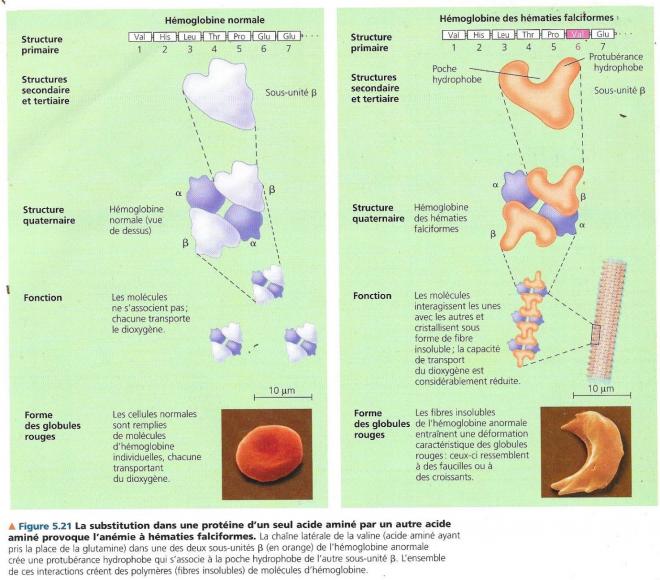
5.5.4 facteurs déterminant la conformation d’une protéine.
La forme unique d’une protéine détermine sa fonction. Quels sont les facteurs qui déterminent cette conformation ?
Essentiellement, lorsqu’un polypeptide est synthétisé, il prend spontanément une forme tridimensionnelle déterminée par la séquence des acides aminés et leurs interactions attractives mutuelles
Mais cette forme dépend aussi du milieu physico-chimique dans lequel la protéine baigne. Si le pH, les concentrations en sel, la température ou d’autres facteurs sont modifiés, la protéine peut se dérouler et perdre sa configuration initiale, on dit que la protéine est dénaturée.
La plupart des protéines sont dénaturées lorsqu’elles passent d’un milieu aqueux un solvant organique comme l’éther ou le chloroforme. Dans ces milieux, les parties hydrophobes des protéines s’orientent vers l’extérieur, en contact avec le solvant (la protéine se retourne comme un gant). D’autres substances chimiques peuvent également briser les ponts hydrogène, les ponts « disulfure » et les liaisons ioniques dont dépend la conformation de la protéine. La chaleur excessive peut également dénaturer la protéine en agitant suffisamment les chaînes polypeptidiques pour vaincre les interactions faibles qui stabilisent la conformation de la macromolécule C’est ainsi que le blanc d’œuf devient opaque à la cuisson, en effet, les protéines qui le composent sont dénaturées par la chaleur et deviennent insolubles et coagulent.
Une protéine dénaturée dans une éprouvette, par des produits chimiques ou par l’action de la chaleur reprend souvent sa forme fonctionnelle lorsque l’agent dénaturant disparaît ; c’est donc la structure primaire qui contient l’information nécessaire à l’obtention d’une forme spécifique. C’est donc la séquence des acides aminés qui détermine la conformation d’une protéine, c’est-à-dire les endroits où se forment les hélices α, les feuillets β plissés, les ponts disulfure, hydrogène, les liaisons ioniques. Ce repliement correct est cependant plus difficile dans un endroit encombré comme le milieu cellulaire.
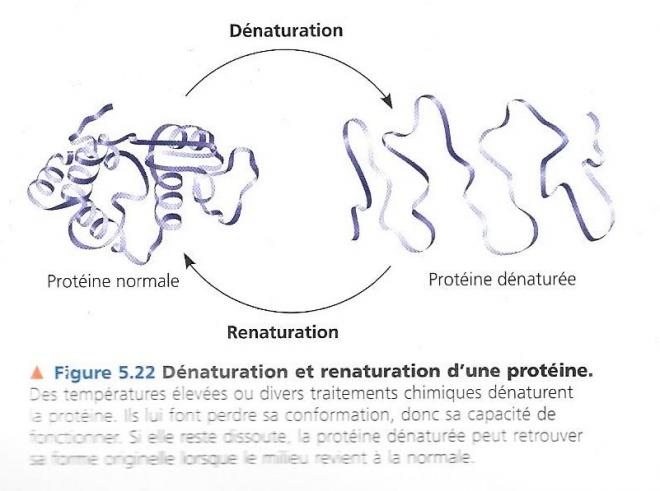
5.5.5 Le mystère du repliement des protéines.
A peu près 900.000 protéines sont connues par leur séquence d’acides aminés des biochimistes. La structure tridimensionnelle n’est connue par- contre que pour 7500 protéines. Théoriquement, il devrait être possible d’établir une corrélation entre séquence en acides aminés et structure tridimensionnelle. Le mystère n’est cependant pas résolu et la plupart des protéines passent probablement par plusieurs stades intermédiaires avant d’adopter une configuration stable. L’étude de ces conformations ne révèle cependant pas ces stades. Les biochimistes ont cependant élaboré des méthodes pour suivre les étapes intermédiaires de la formation d’une protéine. Les chercheurs ont également découvert des chaperonines (aussi appelées chaperons moléculaires. Il s’agit de molécules protéiques qui favorisent le repliement adéquat des autres protéines. Les chaperonines ne dictent pas la structure finale d’un polypeptide.
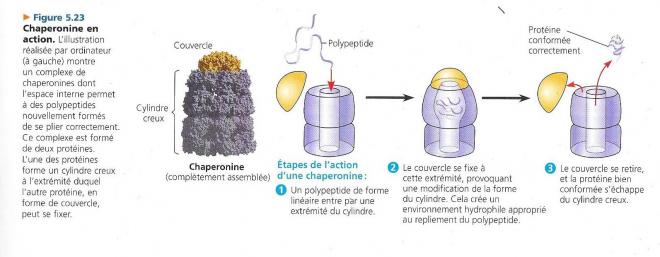
Lorsque les scientifiques sont en présence d’une vraie protéine, il ne leur est pas facile de déterminer sa structure tridimensionnelle exacte étant donné qu’elle est constituée de milliers d’atomes. La cristallographie par diffraction de rayons X est particulièrement utile pour effectuer cette tâche. La résonance magnétique nucléaire, qui ne nécessite pas de cristallisation de la macromolécule a récemment été mise en œuvre.
Elles empêchent plutôt le nouveau polypeptide de céder pendant son repliement spontané aux « mauvaises influences qui se manifestent dans l’environnement cytoplasmique. La bactérie E.coli abrite une chaperonine bien connue. Il s’agit d’une multi-protéine ayant l’aspect d’un cylindre creux dont la cavité sert d’abri à divers polypeptides en processus de repliement.
5.6 : Les acides nucléiques emmagasinent et transmettent l’information génétique
La séquence primaire en acides aminés détermine la conformation de la protéine et le déterminant de cette séquence et programmée par une unité d’information génétique appelée gène. Les gènes se composent d’ADN, un polymère appartenant à la classe de composés appelés acides nucléiques
5.6.1 Le rôle des acides nucléiques.
Il existe deux types d’acides nucléiques, l’acide désoxy-ribonucléique ADN et l’acide ribonucléique ARN. Ces molécules permettent aux organismes de reproduire leurs compétences et leurs composantes complexes d’une génération à l’autre. Unique en son genre, l’ADN fournit les directives de sa propre réplication. Il dirige également la synthèse d’ARN et ce faisant la synthèse des protéines.
L’ADN est le matériel génétique que les parents lèguent à leur progéniture. Chaque chromosome contient une longue molécule d’ADN de plusieurs centaines ou plusieurs milliers de gènes. Lorsqu’une cellule se reproduit en se divisant, ses molécules d’ADN sont copiées et transmises à la génération suivante. Les instructions qui programment toutes les activités de la cellule sont encodées dans la structure de l’ADN.
L’ADN peut-être comparé à un logiciel qui a besoin de matériel informatique pour réaliser les instructions qu’il contient. Tout comme il faut une imprimante pour imprimer un texte ou un lecteur de code-barre, il faut à l’ADN des protéines pour exécuter un programme génétique. Les protéines sont à la cellule ce que la matériel informatique est à l’ordinateur. Par exemple c’est l’hémoglobine et non l’ADN qui transporte le dioxygène. Dans le sang. L’ADN, lui, spécifie la structure de l’hémoglobine.
L’ARN sert d’intermédiaire entre l’ADN et les protéines. Chaque gène présent sur l’ADN dirige la synthèse d’un type d’ARN appelé ARNmessager (ARNm). C’est ARNm interagit ensuite avec la molécule de synthèse protéique qui permet la production du polypeptide « demandé ». Les sites de la synthèse protéiques sont des organites appelés ribosomes.
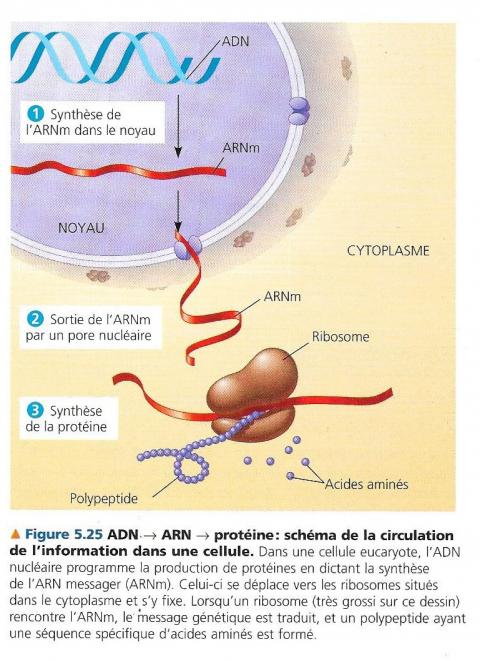
Chez les eucaryotes, l’ADN est dans le noyau et les ribosomes dans le cytoplasme, l’ARNm transfère donc l’information du noyau au cytoplasme. Chez les procaryotes il n’y a pas de noyau mais c’est également l’ARN qui transmet l’information au ribosome et à d’autres organites pour commander la synthèse des polypeptides.
5.6.2 La structure des acides nucléiques
5.6.2.1 Introduction
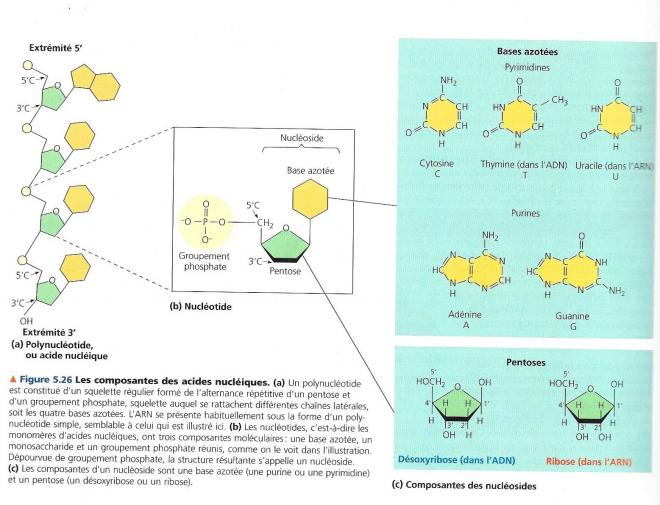


5.6.2.2 Les monomères des nucléotides
Voyons en premier lieu les deux composantes d’un nucléoside : une base azotée et un monosaccharide.
Il y a deux familles de bases azotées :
- Les pyrimidines
- Un seul cycle de 4 atomes de carbone et de deux atomes d’azote (hétérocycle)
- Son azote tend à capter des H+ (base azotée)
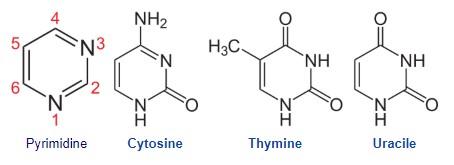
b.Les purines
- Masse moléculaire plus importante que les pyrimidines car un cycle de 6 atomes accolé à un cycle de 5 atomes
- Il s’agit également de deux hétérocyles azotés avec la même fonction basique
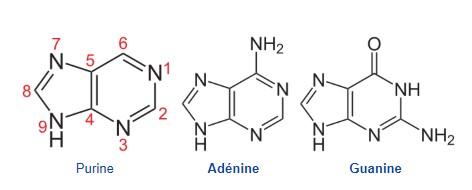
Pyrimidines : Thymine, Cytosine, Uracile (T,C,U)
Purines : Adénine, Guanine (A,G)
Elles portent toutes des groupes fonctionnels : La thymine est méthylée, cytosine, adénine et guanine sont aminées…
|
L’Adénine, la Cytosine et la guanine entrent toutes les trois dans la composition de l’ARN comme l’ADN. La thymine quant à elle se trouve uniquement dans l’ADN et l’uracile uniquement dans l’ARN.
|
Il y a deux monosaccharides différents
Dans un nucléotide, la base azotée est toujours associée à un pentose (sucre en C5).
Les nucléotides de l’ARN contiennent le ribose
Les nucléotides de l’ADN contiennent le désoxyribose.
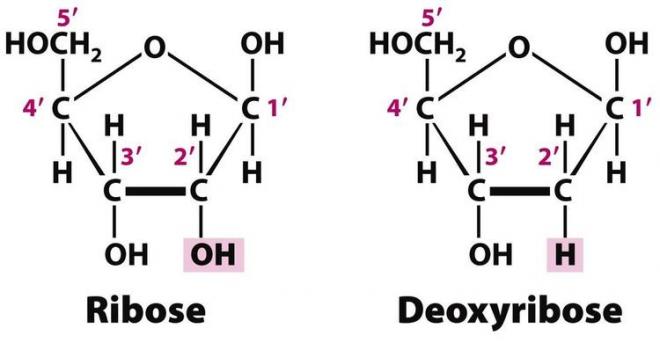
Il n’existe qu’une seule différence entre ces deux monosaccharides : il n’y a pas d’atome d’oxygène lié au second atome de carbone du cycle du désoxyribose, d’où son nom.
Le groupement -OH étant un groupe réactif, le désoxyribose est plus stable que le ribose.
Il convient de distinguer la numérotation des atomes de la base azotée et celle des monosaccharides. On ajoute donc un prime (‘) à la suite du numéro des atomes de carbone du cycle du monosaccharide. Ainsi l’atome de carbone qui est situé au-dessus du cycle est nommé 5’….le pentose de l’ADN est le 2’désoxyribose ( désoxygéné en 2’). La base azotée, quant à elle, est liée au carbone 1’ du pentose
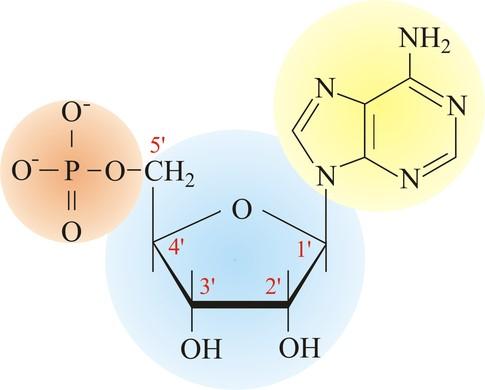
Nous venons d’établir la structure d’un nucléoside, il convient maintenant de voir comment il est modifié pour donner un nucléotide.
Il s’agit d’attacher un groupement phosphate au carbone 5’ du pentose.
 La molécule devient alors un nucléoside monophosphate (un nucléotide). Exemple d’un ribonucléotide (ribose) construit avec l’Adénine.
La molécule devient alors un nucléoside monophosphate (un nucléotide). Exemple d’un ribonucléotide (ribose) construit avec l’Adénine.
Il existe plusieurs types de nucléotides qui n’entrent pas dans la composition des acides nucléiques, par exemple l’ATP dont nous verrons la grande importance plus loin.
5.6.2.3 Les polymères des nucléotides
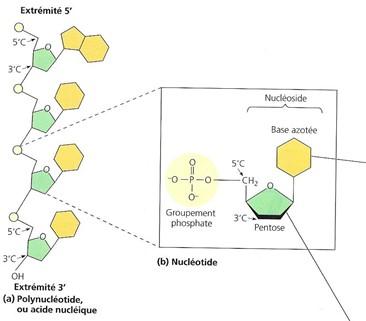
Les nucléotides sont unis les uns aux autres par une liaison phosphodiester pour donner naissance à une chaîne de plusieurs dizaines à plusieurs millions d'unités. La liaison phosphodiester elle se fait entre deux nucléotides contigus (l'un au-dessus de l'autre). Entre le 3'OH de l'un et le 5'phosphate de l'autre.
Cela forme un squelette dont la séquence d’unités pentose-phosphate se répète. Les deux extrémités libres du polymère sont différentes. L’une se termine par un groupement phosphate attaché à un carbone 5’, tandis que l’autre porte un groupement hydroxyle sur un carbone 3’. On les appelle respectivement l’extrémité 5’ et l’extrémité 3’.
Chaque brin d’ADN possède donc une orientation intégrée le long de son squelette pentose-phosphate. Tout le long de ce squelette pentose-phosphate se trouvent attachées des chaînes latérales constituées d’une base azotée.
Cette séquence de bases azotées constitue ainsi la structure primaire du polymère d’ADN ou d’ARNm et celle-ci est typique de chaque gène.
L’information d’un gène se trouve encodée dans la séquence spécifique des quatre bases azotées de l’ADN
La structure primaire ainsi constituée détermine la séquence polypeptidique des protéines, donc leur conformation tridimensionnelle et leur fonction.
Date de dernière mise à jour : 29/11/2018
Commentaires
-
 Whoa! This blog looks just like my old one! It's on a completely different topic but it has pretty much the same layout and design. Great choice of colors!
Whoa! This blog looks just like my old one! It's on a completely different topic but it has pretty much the same layout and design. Great choice of colors! -
 Wonderful items from you, man. I've be mindful your stuff previous to and you are just extremely magnificent. I actually like what you have acquired right here, really like what you are saying and the way wherein you assert it. You're making it entertaining and you continue to care for to stay it sensible. I can not wait to learn far more from you. This is really a terrific website.
Wonderful items from you, man. I've be mindful your stuff previous to and you are just extremely magnificent. I actually like what you have acquired right here, really like what you are saying and the way wherein you assert it. You're making it entertaining and you continue to care for to stay it sensible. I can not wait to learn far more from you. This is really a terrific website.
Ajouter un commentaire